Descript macht mit Voice Cloning den nächsten Schritt in der KI-Podcast- und Videobearbeitung
Jay LeBoeuf spricht darüber, wie Descript mithilfe von künstlicher Intelligenz die Audio- und Videobearbeitung so einfach macht wie die Bearbeitung von Texten. Dazu gehört auch Overdub, eine neue Funktion von Descript zum Klonen von Stimmen.

Um die Audio- und Videobearbeitung mit herkömmlicher Software und ihren Dutzenden von Tools und Panels zu erlernen und zu beherrschen, sind oft Monate und Jahre nötig. Das 2017 gegründete Start-up Descript verfolgte eine einfache, aber ehrgeizige Idee: Wie wäre es, wenn man Videomaterial allein durch die Bearbeitung von Text bearbeiten könnte? Und noch besser: Was wäre, wenn dieser Text aus einem Transkript stammt, das von Ihrer Bearbeitungsanwendung automatisch erstellt wird?
Mit generativer KI und Sprachverarbeitung gibt Descript allen Kreativen die Möglichkeit, Content in professioneller Qualität selbst zu schneiden. Audio- oder Videodateien werden automatisch in eine Textdatei transkribiert. Benutzer/innen können dann Text ausschneiden, einfügen und löschen – die Audio- oder Videodateien werden automatisch entsprechend angepasst.
Stripe sprach mit Jay LeBoeuf, dem Chef der Geschäfts- und Unternehmensentwicklung von Descript und einem Veteranen auf dem Gebiet der Sprach- und Audioerkennung. Wir haben ihn gefragt, wie das Unternehmen das kreative Potenzial der KI mit ihren Risiken in Einklang bringt. Und wir sprachen mit ihm über die Voice-Clone-Funktion Overdub und darüber, wie Descript von der Zusammenarbeit mit Stripe profitiert hat. Das Interview, das wir auf Descript transkribiert haben, wurde aus Gründen der Klarheit bearbeitet und gekürzt.
Wie kamen Sie auf die Idee, die Audio- und Videobearbeitung wie die Bearbeitung eines Word-Dokuments zu gestalten?
Menschen sind von Natur aus Geschichtenerzähler. Wir alle können mit Wort und Schrift umgehen, wenn wir eine Idee festhalten möchten. Text ist etwas sehr Vertrautes, ganz gleich, ob man als Anfänger keine Ahnung hat, was eine Wellenform ist, oder ob man als Profi genau weiß, wie man seine Geschichte strukturieren möchte.
Was zeichnet Ihr Produkt im Vergleich zu anderen Transkriptionstechnologien aus?
Unsere Technologie ermöglicht eine nahtlose Bearbeitung. Zum einen wird das Transkript perfekt an Ihr Audiomaterial angepasst, sodass alle vorgenommenen Änderungen genau an der von Ihnen gewünschten Stelle erfolgen, wobei Schnitte praktisch nicht zu erkennen sind. Wenn ich z. B. etwas gesagt habe und Sie es mit Descript herausschneiden wollen, entsteht keine Lücke – es wird nicht so klingen, als hätte ich mitten im Satz Luft geholt. Es wird sich auch nicht wie ein schlecht bearbeiteter Jump Cut anhören, sondern es wird alles so funktionieren, als hätte es ein Profi bearbeitet.
Das alles umfasst hochentwickelte Technologien, wovon Sie aber kaum etwas bemerken. In einer typischen Descript-Videobearbeitung können Sie elf Mal KI nutzen, ohne dass Sie überhaupt wissen, dass die KI an Ihrer Kreation gearbeitet hat.
Wow! Zum Beispiel?
Wir nehmen gerade dieses Interview auf. Stellen wir uns vor, Sie nehmen die Datei und ziehen sie in Descript. Dies ist die erste Instanz der KI, bei der alle Wörter in der Datei transkribiert werden und als Text erscheinen. Dann haben wir eine KI, die die Sprecher erkennt. Descript weiß also, wann Sie sprechen und wann ich spreche.
Unsere KI kann auch automatisch die Tonqualität der Aufnahme verbessern. Ich habe hier ein gutes Mikrofon, aber viele Leute arbeiten in Umgebungen, deren Akustik nicht professionell klingt. Also haben wir eine Technologie namens Studio Sound entwickelt, die jede Person so klingen lässt, als befände sie sich im Tonstudio eines Radiosenders.
Das System kann auch natürliche Sprache verarbeiten. So können alle „Ähs“ und sonstige Füllwörter, die beim Erzählen einer Geschichte stören, mit nur einem Knopfdruck herausgeschnitten werden.
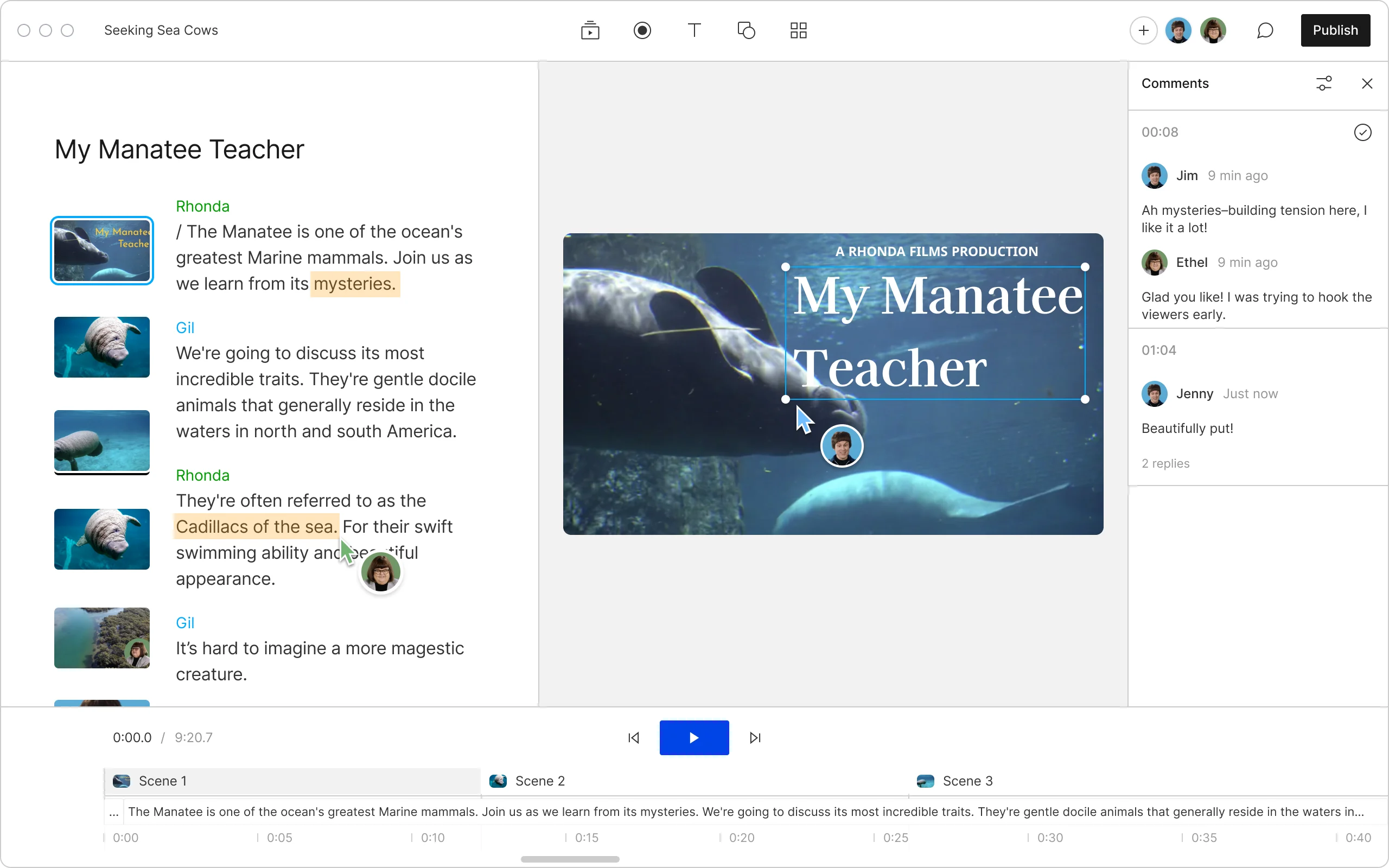
Ein Screenshot der Descript-App.
Manchmal können Füllwörter oder lange Pausen für Struktur sorgen. Wie eine dramaturgische Pause. Kann Ihre Technologie zwischen sinnvollen Pausen und überflüssigen „Ähs“ unterscheiden?
Selbstverständlich. Wir wissen, dass Füllwörter und Pausen zur Glaubwürdigkeit, Authentizität und Aussagekraft beitragen können. Wir haben zwar ein Tool zum Entfernen von Füllwörtern mit einem Klick, aber wir ermöglichen es den Nutzerinnen und Nutzern auch, Änderungen an bestimmten Stellen vorzunehmen. Wir betrachten KI als ein Workflow-Tool in den Händen eines versierten Geschichtenerzählers.
Können Sie etwas darüber sagen, wie Descript die Fähigkeit der KI, neue Sprache zu generieren, integriert?
Wir haben eine Sprachtechnologie namens Overdub entwickelt. Mit ihr kann jede/jeder die eigene Stimme klonen – und nur die.
Nehmen wir an, ich produziere einen Podcast. Ich erstelle das Rohmaterial für eine Folge, stelle dann aber fest, dass ich Fehler gemacht habe. Beispielsweise nenne ich einen Gast versehentlich „Sam“ statt „Henry“. Ich habe nun meinen eigenen Jay-Stimmenklon erstellt, mit dem ich das korrigieren kann. Dazu musste ich nur zehn Minuten in ein Mikrofon sprechen, um Overdub mit genügend Material zu versorgen. Ich doppelklicke auf „Henry“ und gebe „Sam“ ein. Overdub wird mich dann in der gleichen akustischen Umgebung synthetisieren und den richtigen Namen sagen.
Overdub ist bei unseren Unternehmensanwendern sehr beliebt, insbesondere im Produktmarketing.
Warum?
Angenommen, Sie müssen Produktnamen aktualisieren oder Informationen darüber, wo etwas zu finden ist. Sie können auswählen, was zu korrigieren ist, und es neu eingeben, anstatt es neu aufzunehmen. Oder nehmen wir an, Sie sind der Sprecher einer Produktdemo und Ihnen fällt auf, dass Sie eine Anweisung hinzufügen müssen, in der erklärt wird, wie die Benutzer/innen weitere Informationen erhalten können. Sie können einfach ganze Sätze eintippen und Overdub übernimmt das Voiceover.
Und wenn jemand versucht, meine Stimme ohne meine Einwilligung zu klonen?
Wenn Sie Ihre Overdub-Stimme erstellen, müssen Sie nicht nur Material liefern, aus dem hervorgeht, wie Sie klingen, sondern auch live eine Einwilligungserklärung vorlesen. Wir nehmen diese Einwilligungserklärung und gleichen sie sowohl algorithmisch mit einem Fingerabdruck der Stimme als auch durch ein Team von Menschen mit Kopfhörern ab, um sicherzustellen, dass wirklich Sie es sind und dass Ihr Audiomaterial mit Ihrer Einwilligung übereinstimmt.

Overdub, die Voice-Clone-Funktion von Descript, ermöglicht die Verwendung eines Text-to-Speech-Modells der eigenen Stimme oder den Einsatz extrem realistischer Standardstimmen.
Können Sie uns etwas über Ihre Beziehung zu Stripe erzählen?
Wir verwenden eine Reihe von Stripe-Produkten, die miteinander kombiniert sind: die Zahlungsplattform von Stripe, Billing, Radar, Sigma und Revenue Recognition. Es war sehr hilfreich, Abwicklung, Abonnements, Abrechnung und Recognition zentral zu konsolidieren. Wir sparen Kosten, aber es bedeutet auch weniger Komplexität, da auf unserer Seite weniger Technik zur Systemintegration erforderlich ist. Stripe ist ein außerordentlich entwicklerfreundlicher Partner.
Wie geht Stripe auf die Entwicklungsteams ein?
Zum einen stellt die API-Dokumentation den Goldstandard dar. Aus Dingen wie der Aufnahme von Test-Keys in Code-Beispiele wird deutlich, dass Stripe darauf achtet, dass die API einfach zu integrieren ist.
Zum anderen ist Stripe sehr reaktionsschnell. Wir haben am Betatest für Revenue Recognition teilgenommen und hatten mehrere Treffen mit den Produkt- und Abrechnungsteams, bei denen das Stripe-Team sich Zeit genommen hat, um uns durch die Änderungen zu führen. Auch beim Testen von Webhooks gab es mehrere Verbesserungen. Stripe arbeitet ständig daran, die Erfahrung zu verbessern.
Wird Descript irgendwann mithilfe von Sprachmodellen konkrete Inhalte vorschlagen können, die dann mit Overdub erstellt werden könnten?
Wir haben kürzlich eine ChatGPT-4-Integration vorgestellt, die bald verfügbar sein wird. Wie die aussehen könnte? Was Sie erwähnt haben, ist eine Möglichkeit, von der uns die Nutzer/innen sagen, dass sie sie gerne hätten. Es ist großartig, OpenAI als Partner zu haben, und ich denke, alle werden begeistert sein von dem, was wir dieses Jahr herausbringen werden.

